
Abstract
Imagine, every time to see the beauty of the sunset, you will be photographed, and then send on social media.Before you a few photos there are a lot of people ' ' ' ', but one day you send pictures of only a few ' ' ' ', then you will continue to send the sunset photos?We will make a choice, then see what happens, it will affect the choice of our future.Neuroscience researchers have developed a mathematical model, to explain how people can choose from them in both positive and negative results of learning.These models are often referred to asReinforcement learning model.In this article, we will explain in the real world using reinforcement learning, a mathematical equation for how to help us understand the process, as well as how the brain by learning from experience to make a good choice.
What is learning?
Reinforcement learning is a process, in this process, we use the past experience to help us make a good choice, in order to get good results.Let's look at the article in detail described in the example.When you release the sunset picture for the first time, you will get a lot of ' ' ' ', it makes you happy - accept all these 'praise' positive experience makes you more likely to be released another photograph.Did you send the second sunset photo and got the same number of 'great';You released the third and got more ' ' ' '.But one day, you release the do you think of the picture is very beautiful but almost no one ' ' ' '.On the contrary, some of your photo wrote a mean comments.Suddenly, not all related to release the sunset picture is a positive experience.So you need to update the experience, receive vitriolic remarks of the negative experience.The next time you release the possibility of sunset will be more lower.
We choose the results can be consideredTo strengthen the signal.If we make a choice and experience is very good, positive reinforcement signal, we are more likely to repeat the choice in the future.However, if we make a decision and experience is not good, we may choose a different option next time.This process is called reinforcement learning.
Why use mathematical equation to understand learning and decision making
Generally speaking, the positive experiences (such as on social media by a large number of "praise") can cause us to increase hope for reward, and negative experiences (such as by vitriolic remarks) can reduce the we hope for reward.But, what level of feedback can lead to change we are looking forward to?For example, suppose you released nine received many 'praise' pictures and a picture of a received hate comments.To what extent a nasty comments will affect your expected rewards to publish pictures?How likely it is that you post similar picture in the future?If there are no mathematical equations to describe the learning process, we will not be able to answer these questions.
In addition, the researchers can write with a different part of the equation, each part represents the thinking or involved in the decision-making process.Then, through the change every part of the equation, we can see the other part of the how to change, to help us understand how different thinking process will affect learning.
Rescorla - Wagner model
Over the years, researchers have proposed different mathematical equations -- or ' 'Calculation model' 'to explain how people learn from positive and negative experience.The first one of the models have been proposed, and is called thinking [le Wagner (Rescorla - Wagner) model1,2].
Researcher Robert ⋅ ⋅ thinking and Alan Wagner hoped to better understand another researcher Pavlov's famous experiment.In these experiments, Pavlov every time a bell (it is actually a voice device, a metronome, but for the sake of simplicity, we call the bell), will give the dog food.At first, the dogs did not bring food reward with the bell.But Pavlov found that after several times to repeat the process, even if you don't give them food, the dog would start drooling when hearing the bell.These results show that with the passage of time, the dog will learn to link the bell with food, when they heard the bell, they will be expected to get food (and drool!).
However, as mentioned earlier, is often a studyA gradualIn the process.This means that every time Pavlov's dogs hear the bell with food, they will contact with food to enhance a little bell, and they are more likely to be drooling when the bell rang.
We can predict the dog when hearing the bell for food expect how strong?Can we know how dogs after new experience is expected to change?Rui thinking and Wagner, to put forward a mathematical equation to answer these questions.But they can't just write equation - they need to write a simple equation to accurately reflect the learning process.To do this, they first need to understand how animals learn through experience to establish lenovo.
Rui thinking and Wagner did not try to use the dog, the bell or food, but to use voice and shock in mice.In these experiments, rats will hear the sound and then by electric shock.Usually, the mouse ran in a cage.But the mouse didn't like being shocked, so when they think of impending shock, they often will freeze.Mice will sound with electric shock strength, can through the mice in froze at the sound to measure the length of time.For example, when the mouse for the first time, when they hear a sound not expect electric shock, so it will continue to move normally.However, if it sound and then by electric shocks, the mice will begin to realize that sound and electric shock.The next hearing voices, rats mobile less freeze time longer.
Rui thinking and Wagner, note that, in mice has just started to establish the connection between the voice and electric shocks, they froze in time and frequency change is bigger.And in many times after the shock, they have a more stable patterns of behavior - will freeze, but frozen in time after each shock only increased a little.
This experiment, as well as many other experiments by rui thinking and Wagner found reinforcement learning that ' 'accident"' drive.Animals, in other words, when they encounter the things they didn't expect to learn more.This kind of accident in the process of learning is called ' 'The prediction error', expect to experience things because they represent the animals and the difference between its actual experience things.Pavlov's dogs, for example, the first time I heard the bell, they have no reason to expect any food.When they receive food, they will be an accident, or larger prediction error, because the actual events (food!)And they predict what will happen (not food).Then they realized that there is likely to get food in hearing the bell.The next time when hearing the bellindeedGot food, their prediction error is lower, because they are the results don't too surprised.When they continue to hear the bell and get the food, they look forward to continue to increase of food after hearing the bell, but not before a few higher, because they were more surprised to get the food.
We are always in ' ' ' 'of the prediction error.For example, you may think you don't like to eat broccoli.But one day, you may decide to give it a try and find it really tastes good!In this case, you eat delicious broccoli experiences have different expectations broccoli stupid with you.You will meet the prediction error, which will allow you to learn something about broccoli, and change your opinion about the taste of it.
If there is no prediction error, we won't learn anything by strengthening.For example like to eat pizza.One day, you might be on the way home from the school to stop eating pizza.It's very delicious!In this case, you eat delicious pizza experience no difference with your expectations.Never met the prediction error, so you won't learn anything.Will you continue to think pizza tastes good.
Rui thinking and Wagner wrote a mathematical equation to describe the learning process.Their equations show that animals think something associated with reward (such as ring tones and food), increase how much, this is by its expectations of rewards and the fact that the gap between the decision.(Figure 1)
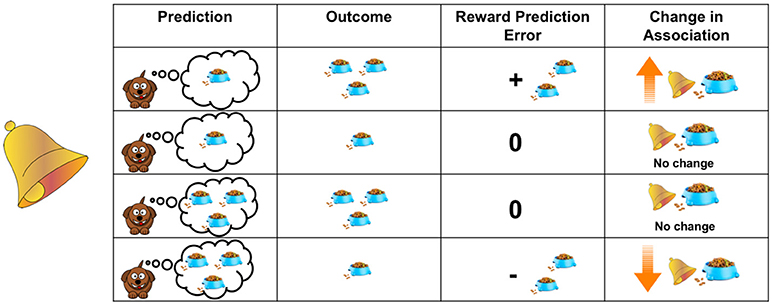
- Figure 1 - learning is driven by the prediction error.
- The table shows the dog's prediction results how to affect their learning and experience.Dog will increase the extent to which the bell and the correlation between food (shown in the fourth column), depending on when it heard the bell actually received food (shown in the second column) and its prediction will receive how much food (shown in the first column).This difference is shown in the third column.
This equation can tell us the animal associated intensity of two things, or a decision (such as post on social media images) could bring much in return.
Equation in addition to the prediction error, and another is called ' 'vector"' terms.vector能告诉我们动物在每次经历后会在多大程度上更新预期,并与预测误差相乘。我们可以将学习率视为每只动物学习的速度。如果动物具有较高的学习率,那么当它遇到预测误差时会更新它的预期。但是,如果动物的学习率较低,那么它可能会更大程度地依赖于过去的所有经历,并且每次经历预测错误时只会稍微改变预期。
How the brain from the reinforcement learning?
Reinforcement learning model helps us to understand the brain's learning style.The brain consists of about 100 billion brain cells called neurons.Neurons release chemicals called neurotransmitters, which can help neurons send messages to each other.dopamineIt is a kind of important neurotransmitters in the brain.dopamine神经元会对我们受到奖励的体验产生反应。
By using the described earlier experiments, scientists have shown that dopamine neurons activity in shows that plays a key role in the brain prediction error.Study found that dopamine neurons to herald a reward things (such as ring), activity will increase, and this is before the real receive rewards.If animals think will get the reward, but no, dopamine neurons activity will be reduced.In terms of reinforcement learning model, we can see the dopamine as dopamine neurons of the prediction error signal - dopamine neurons activities can show the gap between expectations and reality [3].This helps us to learn from strengthening, and ultimately help us to use experience to make access to the choice of rewards,Figure 2).
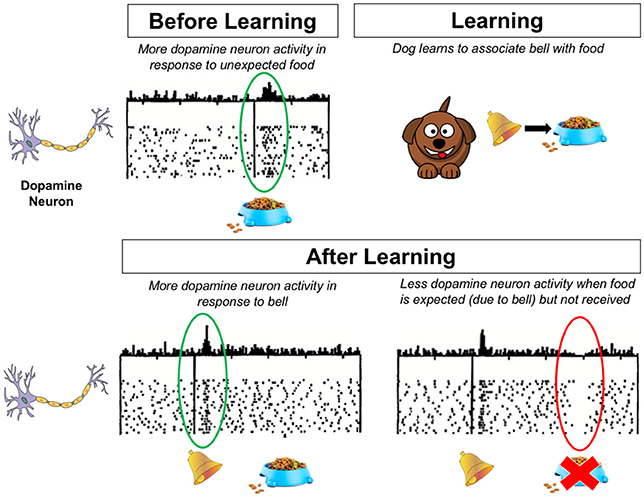
- Figure 2 - the picture shows the before and after learning what happens in the brain.
- Dopamine neurons respond to rewards and expectations of rewards.In the figure some dopamine neurons following the time activities.For a specific point in time, the height of the point at the top of the line says it just below the number of points.Dopamine neurons to reward response, such as food (left).After the dog learn to link the bell with food, dopamine neurons can reward the signal response, such as the bell (lower left).Please note that in this case, the dopamine neurons will not react to the food itself, because it is not surprising.However, if the expected reward, dopamine neurons will become less active (lower right).Derived from Schultz et al. [3].
Many different part of the brain showed similar to dopamine neurons prediction error signal pattern of activity.One is a set of area, deep in the brain called the basal ganglia.Basal ganglia can not only help us learn, but is very important to control our actions and habits.Basal ganglia is the most most in the striatum.Striatal dopamine release is the main part, is to control our response to the incentives of the core part of the brain system.
Many of animal and human studies have shown that the striatum activity related to the prediction error, plays an important role in reinforcement learning [4].Patterns of brain activity associated with the prediction error can also be seen in the brain's frontal cortex, which is an area of participation in decision-making.Striatum and there are many links between the frontal cortex, the contact is very important to help us quickly calculating equation for reinforcement learning, can also explain how we quickly learn from experience, and use this knowledge to help us make future decisions (Figure 3).
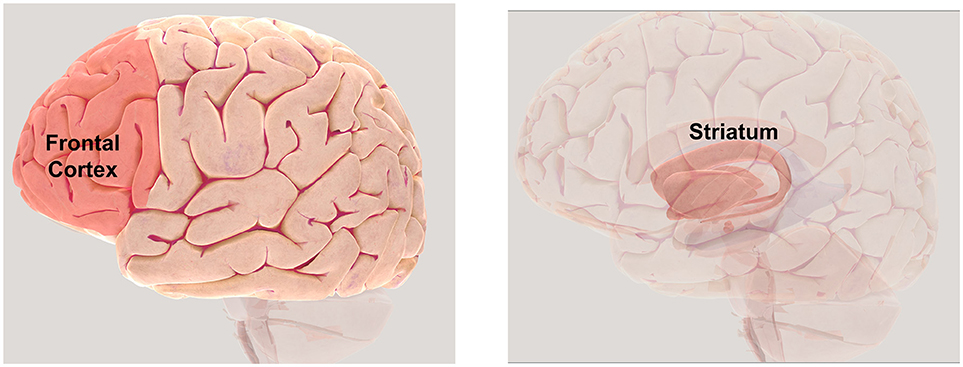
- Figure 3 - the areas of the brain involved in the reinforcement learning.
- Located in the front of the brain (rear) forehead frontal cortex (left) play an important role in the decision-making, striatum (right) shows the prediction error related activities.All rights reserved society for neuroscience (2017).To use the 3 d map to further explore the brain, please visit.http://www.brainfacts.org/3d-brain
However, in the striatum and prefrontal cortex activity changes shown in just a small part of the problem!It is important to remember that the brain is made up of many different parts, the parts work together, to help us to think and do complex things, such as learning.Scientists continue to study the striatum, the frontal cortex and other brain regions that how to work together, to help us learn from strengthening, and finally use the information we learn to make the best decisions.Though we are in this article, introduces the classical learning model thinking - Wagner (Rescorla - Wagner) model, mathematical model, but there is more help us to understand what happens in the brain when learning and learning.
So, the next time when you are considering whether to publish the picture the social media, please remember that your brain is fast solving math problems - and you are not even aware that!
The vocabulary
Computing Model (Computational Model):writeExpressed in simple mathematical calculation model a more complex process.Described in this article the reinforcement learning model is a can represent certain types of learning of the thought process involved in the equation.
The Prediction Error (Prediction Error):writeThe prediction error on behalf of the accident.On behalf of the animals, they expect to experience the content and the difference between the content of the practical experience.
Vector (Learning Rate):writeVector of animals said according to the new information to update its perceived speed.
Dopamine (Dopamine):writeDopamine, is a kind of special type of brain chemicals called neurotransmitters, often participate in the signal.
Conflict of interest statement
The author statement, the study is in no may be interpreted as potential conflicts of interest under the condition of commercial or financial relationships.
reference
[1]writeRescorla, r. 1998. The Pavlovian conditioning.Am Psychol1. The men - 60.
[2]writeRescorla, R., and Wagner, a. r. 1972. 'A found of Pavlovian conditioning: variations in the effectiveness of reinforcement and nonreinforcement,' inClassical Conditioning II: Current Research and foundEds, a. h. Black and w. f. Prokasy (New York, NY: Appleton - Century - Crofts), p. 64-99.
[3]writeSchultz, w., Dayan, P., and Montague, P., r. 1997. A neural substrate of prediction and reward.Science275:1593-9.
[4]writeDayan, P., and the Niv, y. 2008. Reinforcement learning: the good, the bad and the ugly.Curr Opin Neurobiol.She is 5-96 doi: 10.1016 / j.carol carroll onb 2008.08.003